Scaling systems to billion tasks
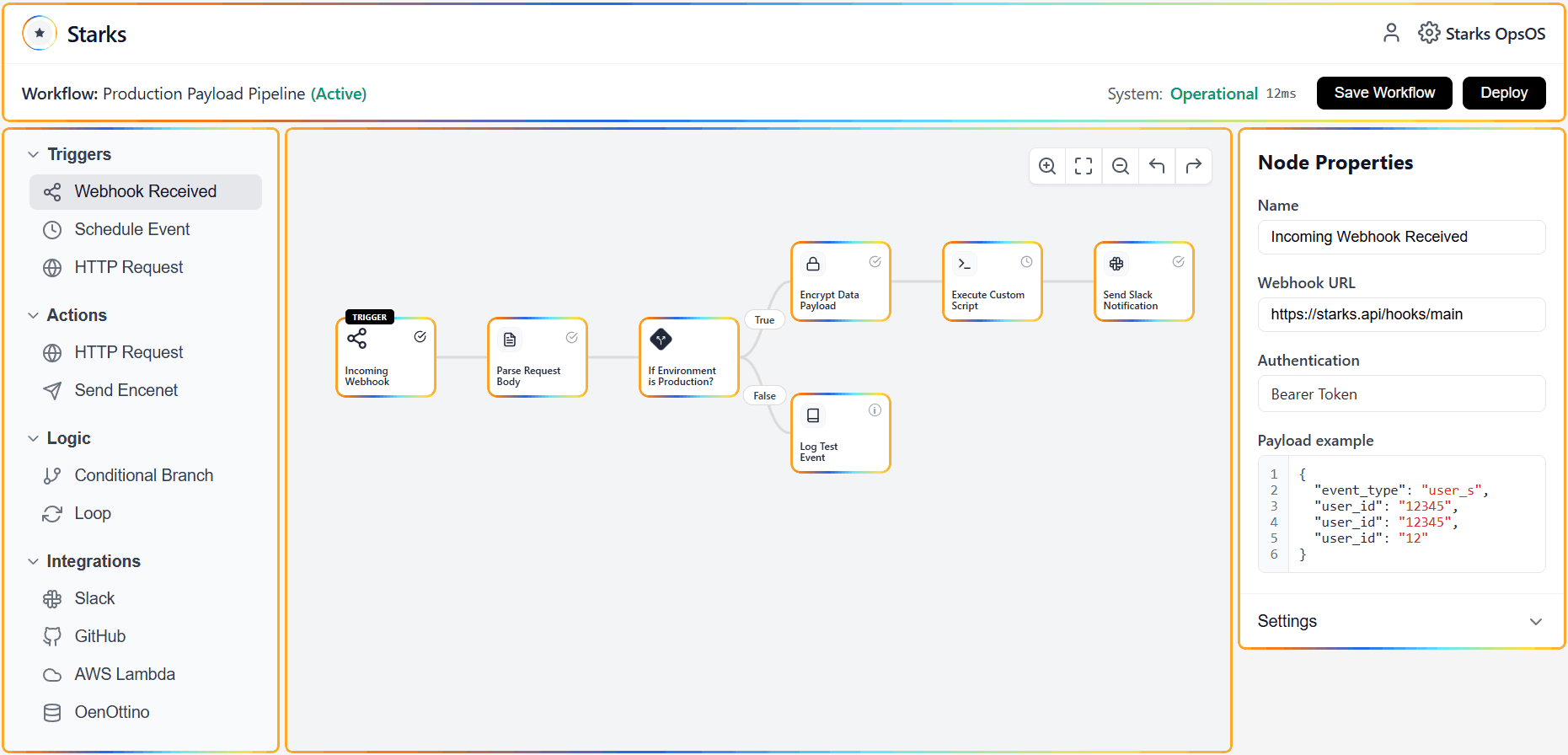
Step 1: Dynamic Database Sharding
Scaling to a billion tasks requires a radical approach to data storage. Starks utilizes an intelligent sharding algorithm that automatically partitions your workflow state across a distributed cluster. This prevents "hot spots" in your database and ensures that write operations remain lightning-fast, regardless of the total volume of data being processed.
Step 2: Kubernetes-Native Orchestration
Our infrastructure is built on a foundation of auto-scaling micro-clusters. Using custom HPA (Horizontal Pod Autoscaler) metrics, Starks monitors incoming throughput at the packet level. When a surge is detected, the system provisions new compute resources in seconds, distributing the load across our 24 global regions to maintain a perfectly flat latency curve.
Step 3: Eventual Consistency & State Sync
To maintain performance at scale, we utilize a sophisticated state management system that balances speed with data integrity. By employing distributed consensus protocols, we ensure that while your execution happens at the edge, your global system state remains synchronized and accurate across all nodes.
The Scalability Promise:
Starks provides a "limitless" ceiling for your growth. We move beyond the traditional bottlenecks of single-instance databases, offering a resilient architecture that sustains massive throughput while maintaining a strict 99.9% uptime guarantee during even the most aggressive traffic spikes.
See More
Expert advice on scaling operations and engineering workflows with absolute clarity.