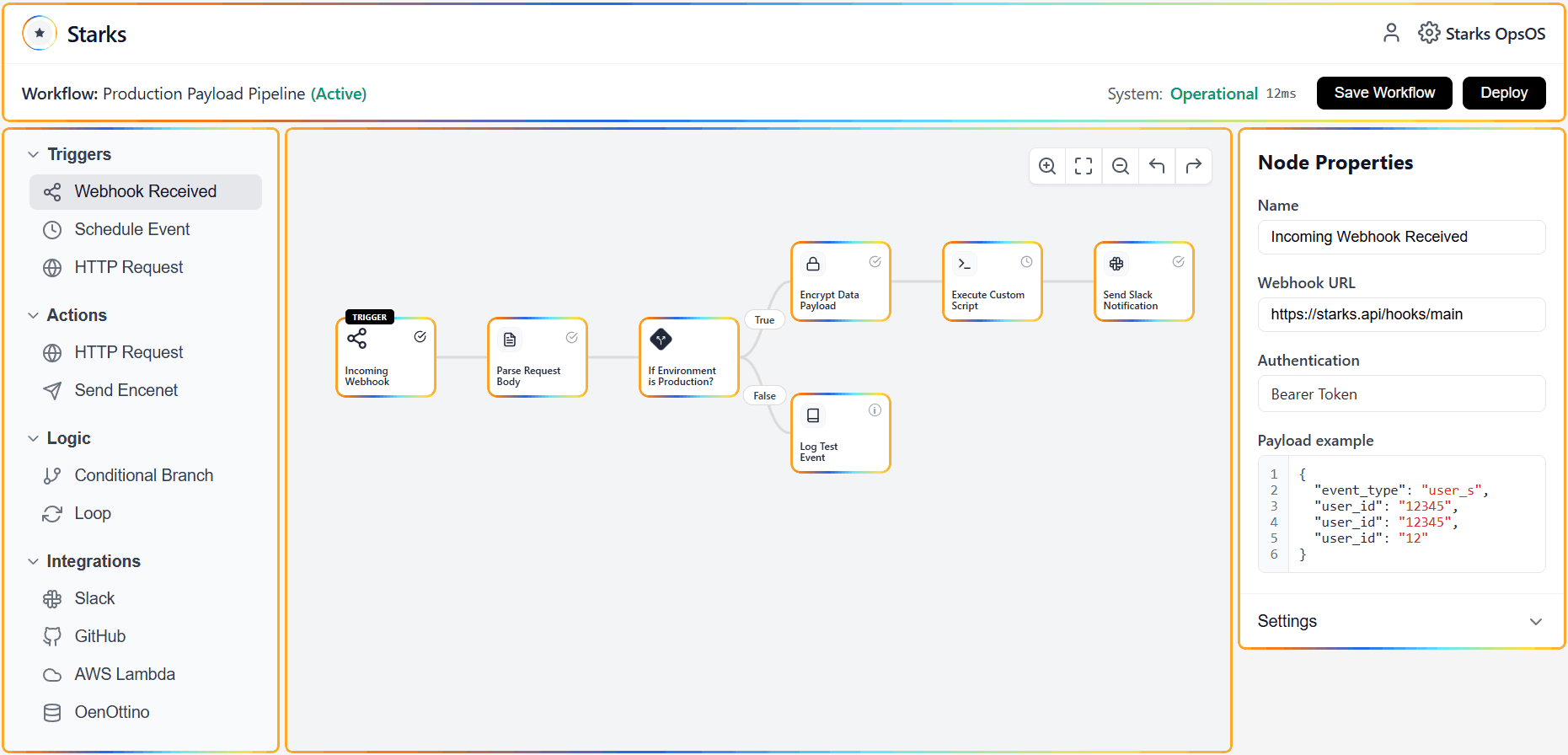
Real time analytics for operations
Step 1: Deep-Packet Telemetry Ingestion
Most analytics tools rely on sampled data, which can hide critical edge-case failures. Starks ingests raw telemetry at the packet level, capturing every execution detail in real-time. This provides a high-definition view of system health, from CPU cycles per node to micro-latencies in third-party API handshakes.
Step 2: Advanced Visualization & Heatmaps
Data is useless if it's not understandable. Our dashboard transforms billions of data points into interactive Global Latency Heatmaps. SRE teams can visually identify which geographical regions or specific infrastructure nodes are underperforming, allowing for targeted optimizations rather than broad, expensive hardware upgrades.
Step 3: AI-Driven Predictive Maintenance
Using a library of historical performance patterns, Starks employs machine learning to identify the early warning signs of system failure. By detecting anomalies in memory usage or request timing before they reach critical thresholds, the system can trigger proactive maintenance workflows to resolve issues before they ever impact a single end-user.
The Clarity Goal:
Starks moves your engineering culture from a reactive "firefighting" mode to a proactive, data-driven strategy. You gain total visibility into the "why" behind your system's performance, turning raw logs into a competitive advantage for your infrastructure.
See More
Expert advice on scaling operations and engineering workflows with absolute clarity.